
by mattbuck, CC-BY-SA 3.0
So, I’ve been trying to come up with a research agenda. I mean, I can’t be the “Framework is stupid” guy forever;1 I don’t want to get pigeonholed.
Anyway, it’s Sunday night and I’m thinking that if I’m going to turn my back on whatever the ACRL comes up with, I’ve still got to have a working concept of “information literacy” (or something to that effect.) Well, I’ve had this idea rattling around for over a year and the other day I finally thought I’d pursue it. So I fired up the LISTA database and started searching for something I figured some librarians somewhere had already researched thoroughly: Bayesian interpretations of information literacy.
Nothing. Not a single article. I checked a few of the major journals. Nada. Google Scholar? Just one 2002 article by Carol Gordon (formerly of Rutgers and clearly on to something). I headed over to Twitter and asked where the rest of the research was? Crickets. From what I can tell, no librarians are applying Bayesian theory to information literacy. Shoot, the impression I’m getting is that most information literacy librarians have never even heard of Bayesian inference. So that’s going to be it. My research agenda will be to introduce a Bayesian approach to information literacy.
But what does that even mean? Here’s a brief overview:
Bayesianism
That formula at the top of this post is the simple form of Bayes’ Theorem. It’s been around for a few hundred years and even though you’ve probably never seen it in library studies, it is absolutely everywhere in information science, cognitive science, legal studies, communication, epistemology, logic, and other assorted fields where people talk about concepts like reliability, credibility, the trustworthiness of information sources, how to evaluate online news, and other things that sound a hell of a lot like “information literacy.” When applied to information literacy, the basic idea behind a Bayesian approach is that your confidence level in the truth of some claim that you’ve read (or watched, heard, etc) is proportional to your confidence level in that claim being true before you read (or watched, or heard, etc) about it times the likelihood that it is actually true. Let’s look at a fairly standard example of Bayes’ Theorem in action.
Suppose there’s a 12% chance that a woman will develop breast cancer (which is scary true). Now, let’s say that contemporary mammograms have an 85% success rate at discovering breast cancer (about right). However, they also have around a 55% false positive rate, meaning they falsely show cancer when there really isn’t any (again, about the right number). Now, if a woman gets her mammogram results back and they come up positive for breast cancer, how worried should she be? This is where Bayes comes in. We’ll start with a slightly extended version of the theory:
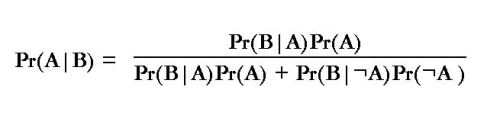
where in our example, the values are like this:
Pr(A|B) = probability of breast cancer given that the mammogram results are positive
Pr(B|A) = probability of positive mammogram results when cancer is actually present. A.K.A., the reliability of the mammogram = 85%
Pr(A) = likelihood of a woman developing breast cancer = 12%
Pr(B|¬A) = probability the mammogram is reporting a false positive = 55%
Pr(¬A) = likelihood a woman does not develop breast cancer = 88% (100% – 12%)
Plugging in the values and you get:

Which means that when a typical mammogram returns a positive diagnosis, there’s only a 17% chance that cancer is actually present.
With me still? Wondering what this has to do with information literacy? Instead of thinking about “does vs. does not have cancer,” how about thinking of “is or is not a fact.” And instead of thinking “how reliable and accurate is this medical test” how about thinking “how reliable and accurate is this information source.” See where I’m going?

by londonmatt on Flickr, CC BY 2.0
Bayesian Information Literacy
Consider the “fake news” problem everyone is talking about. Let’s say your Facebook friend hears that Bernie Sanders can still win the presidential election thanks to “this one weird trick.” You know the kind of story I’m talking about. Now, let’s say that before reading anything but a headline, your friend is already 90% sure that’s not really true, but decides to read anyway. The first article she reads is from U.S. Uncut and she already thinks that U.S. Uncut is a pretty dodgy news source, so she only gives the website around 40% reliability. That is, it’s more unreliable than reliable. Applying Bayesian probability, we can say that her belief changes from 90% to 93% sure it’s not true. As in, if an unlikely piece of news is reported by a source you deem unreliable, you are slightly more inclined to reject the news than accept it. But, let’s say she then reads a CNN article that says the same thing and she thinks CNN is moderately reliable. Maybe CNN reports are more like 75% true. Bayesian approaches allow us to combine her prior confidence from after reading U.S. Uncut with the information from CNN and give your friend room to doubt. Now she’s only 82% sure the story is a fake. She reads more about Bernie’s chances on Occupy Democrats (55% reliable), NPR (90% reliable), and ABC News (80% reliable) and ends up being 91% sure that Bernie still has “one weird trick.” Neat, huh?
Sure, those percentages are just made-up, but the exact numbers aren’t important. And, it’s important to note that this example only addresses her subjective attitudes towards how reliable various sources are. It’s also worth noting that the formula for combining these multiple, sequential prior probabilities is a bit more complicated than the one I put up earlier. Yet, still, broader insights fall out when we think about information literacy in Bayesian terms:
- For any given claim we encounter, we always have a prior credence in that claim being true. Maybe it’s low, maybe it’s neutral, maybe it’s high. Maybe we’ve never heard anything like it before and we’re 50-50. The exact numbers don’t matter. What matters is that what we are inclined to believe after encountering information is proportional to our prior belief times the reliability/credibility we assign to the information source.
- Values like credibility, reliability, or trustworthiness are not binary; they exist on a continuum between 0 and 100%. We need to stop asking “is this source reliable?” and start asking “how reliable is this source given what it is reporting?”
- We are more inclined to believe something if we think it comes from a reliable source.
- We are more inclined to think a source is reliable if we believe what it’s telling us.
- How plausible we deem something is connected to how reliable we think the source reporting it is and vice-versa.
- A single highly reliable source can outweigh several weakly reliable sources.
- But, consistent reporting across multiple weakly reliable sources can yield high levels of belief.
It’s Bayesian inference that explains why your racist uncle believes everything on Breitbart and InfoWars and refuses to accept the New York Times as a legitimate news source. It’s Bayesian inference that explains why a flood of spurious news stories from barely reliable sources can add up to convince otherwise rational people that…yeah, maybe Hillary Clinton did intentionally let Benghazi happen or, yeah, maybe Barack Obama wasn’t born in the United States. It’s not a question of true or false. It’s a question of levels of confidence, and if a news source shared on Facebook says 99 true things and 1 false thing, you’re more likely to believe the false thing at least a little bit. It’s why sites like Breitbart are so successful: the (slight) majority of the things reported on Breitbart are factual, but selectively reported or couched in false claims. Like, right now, the cover story on Breitbart is that Trump hasn’t selected a Secretary of State yet. I think Breitbart is a garbage source for news, but I believe that particular story is most likely factual. Same for the stories about Trump selecting (the asshat voucher-lover) Betsy DeVos as Education Secretary or about some right-wing immigration group arguing that the SPLC should lose tax exempt status. These are plausible, factual stories. They’re selectively reported, to be sure, but they are largely factual. But there’s an article right in the middle defending a alt-right Nazi rally, and this is where we need to think critically about how people engage with information sources, because modern members of the alt-right Nazis aren’t created by late night Mein Kampf study marathons. They don’t get their start on fringe alt-right Nazi websites. They’re wooed by hateful, racist garbage “news” sources that receive a veneer of plausibility by being couched in factually reported information. You tell a student that Breitbart is biased and point to the article defending the alt-right Nazi rally; the student says it’s not and points to the dozen other more-or-less factually correct articles. How do you respond to that? We naturally evaluate information on Bayesian lines, to one degree or another and when we get too subjective with how we assign credibility to sources or too dogmatic/uninformed/etc. about what we want to be true, we stumble into confirmation bias, selective reading, echo chambers, filter bubbles, and so on.Bayes explains it. Check out this NPR story from Friday about a dude who’s built a fake news publishing empire in the San Francisco suburbs. He never explicitly says Bayes, but he absolutely describes how he uses Bayes to manipulate his (mostly right-wing) audience. If peddlers of misinformation and disinformation are using Bayesian concepts to manipulate, shouldn’t we pay attention so we can set things straight?
For anyone interested in “information literacy,” understanding how people actually evaluate sources is vitally important. It also helps as we try to determine how people should evaluate information. Again, these all may sound like obvious observations, but that’s only because Bayesian inference underlies most of our common-sense understanding of how people reason from information sources and I think it’s time library studies took notice. I hope to write more as I learn more, but I can already see several research questions that are unanswerable within the current literature on information literacy, but that might be addressed with Bayesian concepts:
- How do students’ abilities to evaluate information sources change as they read the sources they gather?
- How does prior knowledge affect the ability to evaluate sources?
- What are the information-seeking behaviors of students researching something they have a strong opinion on?
- How do we adjust when our trusted, reliable sources publish something false? For example, when peer-reviewed journals retract articles.
- When gathering sources for an argumentative essay, how does information source reliability/credibility factor into argument strength?
- Are some information sources completely unreliable? Can we ever know how credible an information source is?
- Are “fake news” watch-lists realistic endeavors? If so, how does their provenance affect their accuracy?
- What is the “gap” between how reliable a person thinks a source is compared to how reliable the source actually is? How do we teach to that gap? That is, how do we teach to the student who thinks the New York Times is 99% biased and unreliable when we know that it’s really only 15% biased and unreliable (or whatever number you choose. This is where fact checkers are invaluable in assigning reliability scores.)
I could keep coming up with questions. And if, after this post, I get the impression that this is an area of information literacy that people might be interested in, then I’ll keep asking questions. But, keep in mind that this is a hastily written sketch of Bayesian inference. I can point to a few mathematical errors and omissions I left in for the sake of explaining the general theory better. There’s also a lot of work out there on assigning reliability, assigning confidence levels, estimating prior probabilities, and so on. There’s also a lot of related work that needs to be covered on things like the epistemology of testimony. So this post only barely scratches a scratch on the surface. Here’s the Stanford Encyclopedia of Philosophy entry on Bayesian Epistemology if you’re interested in a longer introduction. You can also just Google it and find hundreds and hundreds of articles and essays delving into Bayesian source evaluation.
So, I don’t know why this has escaped the notice of librarians for so long (Carol excluded!), but it’s where I’d like to take information literacy. And, I’m not just interested in bringing the theories of cognitive science, psychology, information science, economics, philosophy, law, decision theory, and so on into library studies; I’m also interested in asking how librarians can bring their expertise to bear on the problems being investigated in those other, related fields.
What do you think? Does this make any sense at all? I’d love to hear in the comments.
EDIT 11/30/2016: Just to be clear, I’m not saying we should teach students about Bayesian inference. I’m saying that Bayesian theory can help improve our understanding of how people use information. A Bayesian approach can help highlight important concepts that we need to address. How we choose to address those concepts is quite separate.

This was on Flickr, captioned “Do Bayesian networks dream of training data?” Not sure what that means. by plchenttes, CC BY-NC-ND 2.0
ADDENDUMY THING: I was just about to hit post, I stepped away to grab a beer, and I had another thought I want to put down. One of the interesting areas of inquiry with Bayesian inference is how the coherence of our beliefs affects are receptivity to new information. Let’s say there’s a hypothetical person, Jan, who only has three beliefs: (1) Trump won the electoral college, (2) the presidential election was rigged to favor Hillary Clinton, and (3) Trump won the popular vote. Clearly, these aren’t all true, but it’s plausible that Jan believes them. And, importantly, they form a coherent set of beliefs. Now, let’s say we introduce a new piece of information: (4) Hillary Clinton won the popular vote. Bayes tells us that Jan’s willingness to accept (4) is very small given that it does not cohere with (1)-(3). So, the subjective confidence Jan places in an information source reporting (4) is going to have to be incredibly high for Jan to be willing to reassess (1)-(3). That, or an incredibly large number of highly reliable (according to Jan) sources are going to have to consistently report (4) in order to overcome the coherent set of beliefs (1)-(3). Now, think back on your Thanksgiving meal and ask yourself if any of your relatives sound like Jan. Are you a sufficiently reliable source to overcome Jan’s coherent web of beliefs? Interesting, right? (see BonJour’s The Structure of Empirical Knowledge (1985) for an intro to coherentism. I’m not a coherentist per se, but I do think coherence is a huge factor in belief acquisition. Addendumy thing over.
[1] No, but seriously, the Framework is pretty stupid.


“Do Bayesian networks dream of training data?” –Perhaps a play on PKDick’s title “Do Androids Dream of Electric Sheep?”
I definitely had that thought!
Yes, makes a lot of sense. Definitely a research agenda (interesting choice of words, given the topic…) worth pursuing.
Thanks for the vote! And I promise, it’s not *that* kind of agenda. 🙂
This is very much an area of information literacy I’m interested in and this approach to it is very interesting! I’m going to go away and have a good think about what I might be able to do with it, so thank you.
Thomas Bayes, eh? I first heard of him through Nate Silver, then mentioned him in a conclusion to a study I did of area high school students. Louisiana Librearies probably isn’t on everyone’s RSS feed, but here’s the relevant paragraph (without proper layout):
In 1763, Thomas Bayes published
” a probability distribution to represent uncertainty about θ. This distribution represents ‘epistemological’ uncertainty, due to lack of knowledge about the world, rather than ‘aleatory’ probability arising from the essential unpredictability of future events, as may be familiar from games of chance.” (Speigelhalter and Rice)
My own educational mission is to lead students and researchers to an epistemology of information, rather than leaving them to discover information by chance.
This has nothing to do with discovering information by chance. Bayesian epistemology is a well-established, realist approach to an epistemology of information that grows out of externalist conceptions of justification. As I understand it, Bayesian approaches are about ascribing credence levels to testimonial evidence. The SEP has a good survey of the epistemology of testimony: http://plato.stanford.edu/entries/testimony-episprob/
“This has nothing to do with discovering information by chance.”–No, but the typical student or informal research operation has everything to do with it.
This is a very fruitful approach. I think it’s correct that knowledge based on testimony requires an inductive inference about the source, and Bayesian analysis is one account of inductive inference.
If we refused to make any inductive inference about the source of testimony, then we’d have to check everything the source said, using the same evidence the source used, or additional evidence. This might work sometimes, but not often. I can’t check NPR’s story about the fake news publisher, but I still think it’s good to base my beliefs on it.
Here’s another way to understand the induction. We might also be entitled to infer that a testimonial source is generally reliable from (a model of) the source’s process of gathering information. Thus the Bureau of Labor Statistics’ employment and unemployment data are reliable to the extent that these are gathered in reliable ways, allowing the user generally to rely on this data. (Whether the definitions are correct is another matter.)
Peer review is another process for boosting reliability of other kinds of information. Editor review is yet another process.
A limitation of the suggestion I just made is that if testimony isn’t produced by a reliable process, then it’s not rational to base beliefs on that testimony. So the racist uncle, who bases his beliefs on hearsay, lacks any basis for his beliefs. The Bayesian approach says the racist uncle is rational, updating his beliefs on the basis of the information he encounters, although he might encounter only very bad information.
True, the racist uncle might be considered rational, but only to the extent that you can be rational yet still completely incorrect. It all comes down to prior probabilities, and racist uncle is starting from complete falsehoods. Realistically, though, because there are so many other parts of reasoning (induction, deduction, abduction, etc.), I think you’d be hard pressed to find a racist uncle who qualifies as rational across the board.
Otherwise, I agree totally. We derive the vast majority of our knowledge from testimony and we are almost never in a position to thoroughly fact-check our sources. Instead, we rely on heuristics of reliability and Bayesian inference is simply the approach most researchers use in evaluating those heuristics.
Bayesian inference allows us to infer directly to a degree of belief.
“Classical” statistics, the kind used in psychology and many social sciences, understands statistics as drawing inferences about probabilities of *events*, not beliefs.
Applying this to testimony, we look at the testimonial source as a process that can be measured. Then we need to adopt a policy for belief. One policy is that if we *always* rely on BLS data, in the long run we’d *almost* always be correct, although the data might be wrong very infrequently.
A more helpful response:
A search in Web of Science finds 25 articles in either JASIST (now JAIST), Journal of Informetrics, or Scientometrics, with the word, “bayesian,” in the title, abstract, or keywords (So-called “classical” statistics, which tends to pose problems differently from the OP, is dominant in most social sciences.)
Among them this article uses methods like those proposed in the OP:
http://onlinelibrary.wiley.com/doi/10.1002/asi.20377/full
It has 9 citations in WoS, several about medical informetrics.
This is exactly the kind of article that made me pursue this line of thought. I think this sort of inquiry into source evaluation is far more robust than anything going on in library studies. So I think librarians should take note. And even if librarians choose to reject a Bayesian approach to information evaluation, they at least need to acknowledge that there are other approaches to information literacy.
Bayes has come up when I’ve read random articles on statistics and uncertainty, but I could see it being applied in an IL context. The idea of assigning a confidence rating to information sources reminds me of the discussion that happened a couple weeks ago in the Instruction Section listserv about a YELP-like service for information sources. It sounded like a good idea at first, but it would make the person giving the “rating” the sole evaluator and would not give much agency to the person looking at the “review.”
Looking about your approach, I start to think about rationality and testimony/evidence (which you mention) and the impact those could have. Still, explaining to someone that a source is not just 100% reliable or 100% unreliable, but somewhere in between, would be a good place to begin a conversation about the types of decisions one makes when finding/using “good” information.
Do it! I think it is a very worthy project. I’d love to see more of it applied in what we teach / do. I have used a bayes spam filter for years.
I am no mathematician but can see how this theory can help explain to secondary/university students how you can be manipulated by what you read if you don’t consider where it comes from. I would be interested to read more!
[…] « Another take on information literacy, Bayesian inference, and a possible research agenda […]
Have you tried doing a search in PubMed for articles in the medical literature, where Bayesian inference is part of diagnostic reasoning and evidence-based medicine? I am a health sciences librarian at a medical school and teach students about diagnostic test characteristics such as sensitivity, specificity, likelihood ratios, and how diagnostic test results move a physician from X pre-test probability (suspicion of a disease) to Y post-test probability. I believe likelihood ratios are a shorthand for the formula you detail above. You are usually never SURE that the patient has a disease, but you can approach certainty, and there is a greater need to be highly certain if the treatment is expensive or potentially harmful. We also teach student to use p-values and confidence intervals to evaluate published study results to answer the question: “How much do I trust these results?”–on a continuum, as you describe-rather than a blunt “it is/isn’t statistically significant.” I’ve been thinking about this a lot in the aftermath of the election, while I try to figure out how to proceed. The research questions you describe are very interesting.
P.S. As for evidence-based medicine and information literacy, they are so highly related that when I first became aware of EBM I thought for sure that a librarian invented it for job security.
Hi Nancy–
The use of Bayes in the medical literature was certainly an influence. But, I’ve still got a ways to go to review the (massive amount of ) literature on Bayesian inference. 🙂
I’m interested in using Bayesian approaches to solve collection development problems – notably, selecting the sources most likely to be used within a certain time frame. There was some work done in the 1970’s & 1980’s, but I don’t think there has been much done recently. What are your thoughts? I’m new to the approach, but willing to learn.
Hi Karen. I’ve really only been considering the epistemic side of things, not collection analysis. But it sounds interesting. Could you share a citation or two to that previous work from the 70s and 80s? That might help me get situated. Thanks!
[…] robust research methods to study user behavior and assess library services. With that in mind, Lane Wilkinson’s recent post on using Bayesian inference to understand how users contextualize the credibility of an information source strikes me as a […]
[…] norms of the open web. Is that even possible? What can be done when our readers may not be applying Bayesian inference over traditional methods of evaluating the quality and accuracy of information they find? How do we […]
Check out http://www.rootclaim.com . Bayesian analysis of controversial stories in the media.
I love you man. Keep at it.
[…] https://senseandreference.wordpress.com/2016/11/27/information-literacy-bayes-and-a-research-agenda/ (rather technical) […]
[…] norms of the open web. Is that even possible? What can be done when our readers may not be applying Bayesian inference over traditional methods of evaluating the quality and accuracy of information they find? How do we […]
[…] basis of arguing for things that are not true, but possible and perhaps probable… (cue librarian Lane Wilkinson’s understandable efforts to salvage “information literacy” in a post-truth world — I note that even I make the argument to classes that library […]
I think it makes good sense. I just heard the term “information literacy” for the first time, and found my way here by searching for IL and “Bayes theorem”. I often give stats lectures to non-statisticians and introduce Bayes theorem by applying to to urban legends, so the connection seems completely natural to me.
[…] Another take on information literacy, Bayesian inference, and a possible research agenda by Lane Wilkinson https://senseandreference.wordpress.com/2016/11/27/information-literacy-bayes-and-a-research-agenda […]